有序回归的SPSS分析与解释
2017-05-30 MedSci MedSci原创

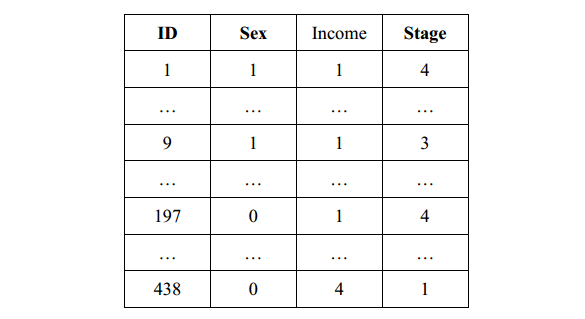
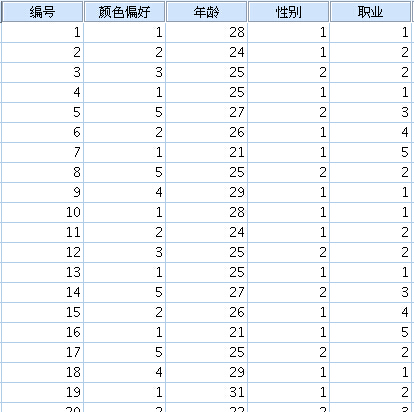
等级回归分析对应的英文为“ordinal regression”,也称有序回归,以等级变量做因变量建立模型来预测危险发生的概率,因变量中各个类别要按不同程度的顺序取值。 第一步:调用界面:分析---回归---有序 选择变量做因变量、因子、协变量。 通过频数描述知,等级越高,概率即数目越多,所以选则“补充对数-对数”即complementary log-
等级回归分析对应的英文为“ordinal regression”,也称有序回归,以等级变量做因变量建立模型来预测危险发生的概率,因变量中各个类别要按不同程度的顺序取值。
![spss教程:回归分析-good:[1]等级回归](https://img.medsci.cn/webeditor/uploadfile/201705/20170530100048258.jpg)
选择变量做因变量、因子、协变量。
通过频数描述知,等级越高,概率即数目越多,所以选则“补充对数-对数”即complementary log-log。

![spss教程:回归分析-good:[1]等级回归](https://img.medsci.cn/webeditor/uploadfile/201705/20170530100050903.jpg)
其中不少知识在以前的文章讲到过的。
单元格信息:最好不要选择,因信息太多,表格输出太大而无法显示。
平行性检验:检验因变量中各类别的斜率是否相等即各类别的参数是否相同,此选项仅对有位置分量(Location component)的模型有效。
“估计响应概率”:“模型估计出的观察单位属于因变量中类别的概率”。
“包含多项常量”:“实际似然比值,含常数项”。
![spss教程:回归分析-good:[1]等级回归](https://img.medsci.cn/webeditor/uploadfile/201705/20170530100050471.jpg)
“度量”:“定义模型中的标度分量”,所选择的变量必须是位置分量所选的变量中的一部分,设置标度分量的目的是改善模型,否则没必要做选择,此处不做选择。
![spss教程:回归分析-good:[1]等级回归](https://img.medsci.cn/webeditor/uploadfile/201705/20170530100050472.jpg)
![spss教程:回归分析-good:[1]等级回归](https://img.medsci.cn/webeditor/uploadfile/201705/20170530100051275.jpg)
由于数据量很大,图片只是一部分的截图。
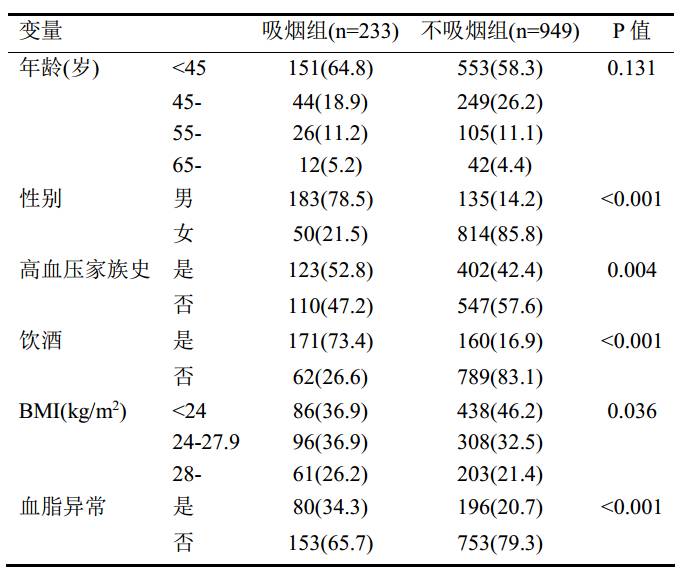
注意观察警告的情况,便于正确理解结果,比如下面的“拟合度”中的显著性,不少数据都是缺失的,有时两种检验的显著性可能不一样,就是因为太多数据缺失造成的。
![spss教程:回归分析-good:[1]等级回归](https://img.medsci.cn/webeditor/uploadfile/201705/20170530100051684.jpg)
“模型拟合信息”:显著性的计算概率可知,小于显著性水平0.05。
“案例处理摘要”:对原始数据的初步统计分析,表格形式如同频数描述一样。
“伪R方”:值越大,模型拟合的越好。
“拟合度”:显著性值越大,说明拟合的越好。有时因为数据缺失,“伪R方”比“拟合度”更有意义。
![spss教程:回归分析-good:[1]等级回归](https://img.medsci.cn/webeditor/uploadfile/201705/20170530100051975.jpg)
“参数估计值”:通过观察显著性P值,看出变量的显著性,P值大的变量说明不显著,剔除掉,或者重新选择模型。
“平行线检验”:由显著性概率知,斜率相同。
最后的预测类别,预测类别概率,实际类别概率都保存在数据窗口中。
![spss教程:回归分析-good:[1]等级回归](https://img.medsci.cn/webeditor/uploadfile/201705/20170530100051901.jpg)
![spss教程:回归分析-good:[1]等级回归](https://img.medsci.cn/webeditor/uploadfile/201705/20170530100051556.jpg)
(1)连接函数选择不准确。解决方法:在Options子对话框的最下方就是link下拉列表,可以选择以上5种连接函数,通过不同的连接函数选择消除该效应。
(2)系数的确在随着分割点发生变化。解决方法:使用无序多分类的Logistic回归分析multinomial logistic
本网站所有内容来源注明为“梅斯医学”或“MedSci原创”的文字、图片和音视频资料,版权均属于梅斯医学所有。非经授权,任何媒体、网站或个人不得转载,授权转载时须注明来源为“梅斯医学”。其它来源的文章系转载文章,或“梅斯号”自媒体发布的文章,仅系出于传递更多信息之目的,本站仅负责审核内容合规,其内容不代表本站立场,本站不负责内容的准确性和版权。如果存在侵权、或不希望被转载的媒体或个人可与我们联系,我们将立即进行删除处理。
在此留言




请问自变量需要设置哑变量吗
113
越来越喜欢读梅斯的文章了,增长了不少知识
98
自变量是选入因子还是协变量框?有没有规定?比方说,是否是这样:连续变量选入协变量,分类变量选入因子框(factor(s))。例子中把性别选入了协变量框,自变量选入哪个框究竟有什么规定呢?还是无所谓
99
感谢梅斯医学!!
103
好文章,学习了,感谢分享。
99
学习谢谢分享
72