
真实世界研究中,如何获得“靠谱”的科研结论?这个SAS实操讲解,科研小白都能学会!
2022-09-23 烤鸭小笼包 MedSci原创

在昨天的这篇文章这波「真实世界研究」热一定要赶上!学会这两个方法=研究成功了一半(纯干货)中,小编向大家介绍了真实世界研究中的混杂因素及其常用的校正方法,特别是倾向性评分匹配和逆概率加权


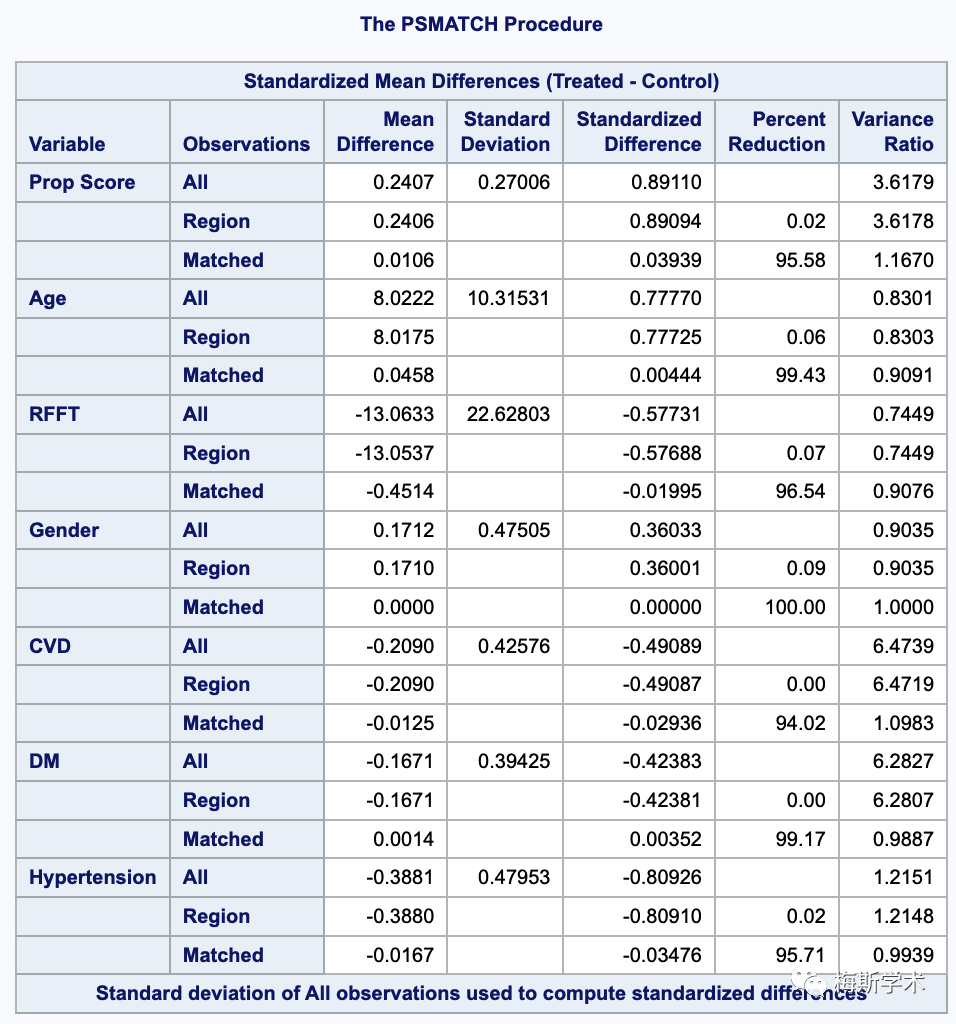
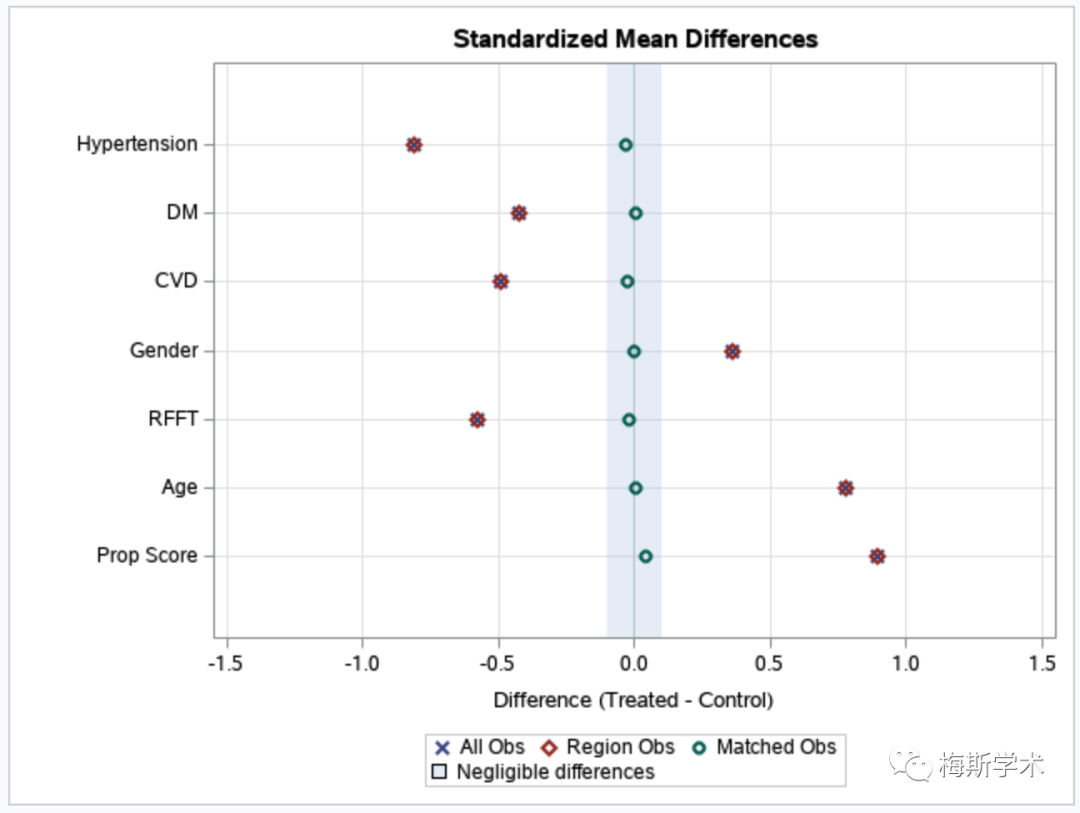
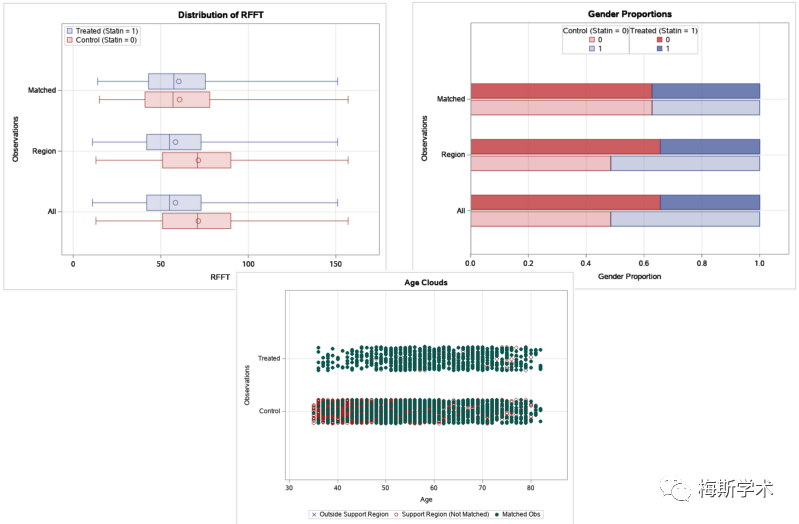
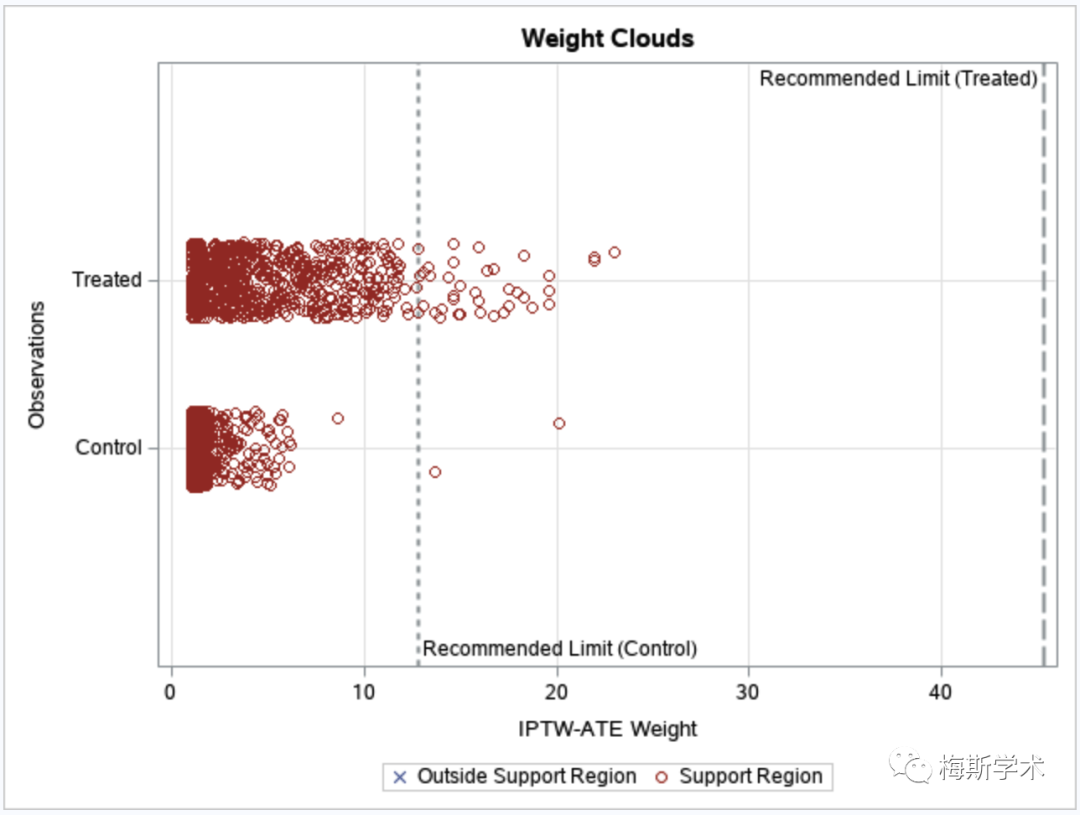
“/”之前的ps和var = 明确了想要评估的对象,“/”之后则告诉SAS我们想要以怎样的方式对这些对象进行评估。SAS会自动生成一个表格,显示匹配前后的PS值和变量组间差异的平均值、方差和标准均值差 (SMD) 等。


本网站所有内容来源注明为“梅斯医学”或“MedSci原创”的文字、图片和音视频资料,版权均属于梅斯医学所有。非经授权,任何媒体、网站或个人不得转载,授权转载时须注明来源为“梅斯医学”。其它来源的文章系转载文章,或“梅斯号”自媒体发布的文章,仅系出于传递更多信息之目的,本站仅负责审核内容合规,其内容不代表本站立场,本站不负责内容的准确性和版权。如果存在侵权、或不希望被转载的媒体或个人可与我们联系,我们将立即进行删除处理。
在此留言









前辈您好,执行到这一步“PSWEIGHT weight = atewgt;“”老报错,实在是找不到原因 PSWEIGHT weight = atewgt; -------- 180 ERROR 180-322: 语句无效或未按正确顺序使用。
82