SPSS 10.0高级教程九:征服一般线性模型
2012-04-12 生物谷 生物谷

请注意,本章的标题用了一些修辞手法,一般线性模型可不是用一章就可以说清楚的,因为它包括的内容实在太多了。 那么,究竟我们用到的哪些分析会包含在其中呢?简而言之:凡是和方差分析粘边的都可以用他来做。比如成组设计的方差分析(即单因素方差分析)、配伍设计的方差分析(即两因素方差分析)、交叉设计的方差分析、析因设计的方差分析、重复测量的方差分析、协方差分析等等。因此,能真正掌握GLM菜单的用法,会使大家
请注意,本章的标题用了一些修辞手法,一般线性模型可不是用一章就可以说清楚的,因为它包括的内容实在太多了。
那么,究竟我们用到的哪些分析会包含在其中呢?简而言之:凡是和方差分析粘边的都可以用他来做。比如成组设计的方差分析(即单因素方差分析)、配伍设计的方差分析(即两因素方差分析)、交叉设计的方差分析、析因设计的方差分析、重复测量的方差分析、协方差分析等等。因此,能真正掌握GLM菜单的用法,会使大家的统计分析能力有极大地提高。
![]() 实际上一般线性模型包括的统计模型还不止这些,我这里举出来的只是从用SPSS作统计分析的角度而言的一些。
实际上一般线性模型包括的统计模型还不止这些,我这里举出来的只是从用SPSS作统计分析的角度而言的一些。
好了,既然一般线性模型的能力如此强大,那么下属的四个子菜单各自的功能是什么呢?请看:
-
Univariate子菜单:四个菜单中的大哥大,绝大部分的方法分析都在这里面进行。
-
Multivariate子菜单:当结果变量(应变量)不止一个时,当然要用他来分析啦!
-
Repeted Measures子菜单:顾名思义,重复测量的数据就要用他来分析,这一点我可能要强调一下,用前两个菜单似乎都可以分析出来结果,但在许多情况下该结果是不正确的,应该用重复测量的分析方法才对(不能再讲了,再讲下去就会扯到多水平模型去了)。
-
Variance Components子菜单:用于作方差成份模型的,这个模型实在太深,不是一时半会说的请的,所以我在这里就干脆不讲了。
出于模型复杂性、篇幅、应用范围及乱七八糟一系列的理由,当然主要是我懒得一一解释,我决定本章采用举例讲解的方式,及讲解一些常见的分析实例,通过这种方法来熟悉那些最为常用的分析方法。
![]() 对统计分析的数据格式不太熟悉的朋友,请一定先去看看统计软件第一课:论统计软件中的数据录入格式,会大有帮助的。
对统计分析的数据格式不太熟悉的朋友,请一定先去看看统计软件第一课:论统计软件中的数据录入格式,会大有帮助的。
§8.1 两因素方差分析
下面的这个例子来自《卫生统计学》第四版,书还没有出来,大家先尝尝鲜。
例8.1 对小白鼠喂以A、B、C三种不同的营养素,目的是了解不同营养素增重的效果。采用随机区组设计方法,以窝别作为划分区组的特征,以消除遗传因素对体重增长的影响。现将同品系同体重的24只小白鼠分为8个区组,每个区组3只小白鼠。三周后体重增量结果(克)列于下表,问小白鼠经三种不同营养素喂养后所增体重有无差别?
|
区组号 |
A营养素 |
B营养素 |
C营养素 |
|
1 |
50.10 |
58.20 |
64.50 |
|
2 |
47.80 |
48.50 |
62.40 |
|
3 |
53.10 |
53.80 |
58.60 |
|
4 |
63.50 |
64.20 |
72.50 |
|
5 |
71.20 |
68.40 |
79.30 |
|
6 |
41.40 |
45.70 |
38.40 |
|
7 |
61.90 |
53.00 |
51.20 |
|
8 |
42.20 |
39.80 |
46.20 |
根据统计分析的要求,我们建立了三个变量来包括上述信息,即group表示区组,food代表使用的营养素,weight表示最终的重量,即:
|
group |
food |
weight |
|
1 |
1 |
50.01 |
|
1 |
2 |
58.20 |
依此类推。
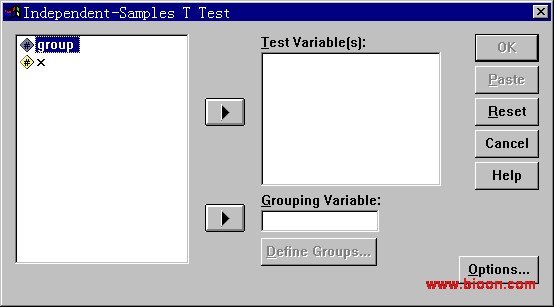
8.1.1 univarate对话框界面说明
这里只有一个结果变量weight,要采用univarate对话框,如下所示:

在上面的这些框框钮钮中,最常用的有:Dependent Variable框、Fixed Factors框、Model钮、Post Hoc钮,下面我们来一一解释。
【Dependent Variable框】
选入需要分析的变量(应变量),只能选入一个。这里我们的应变量为weight,将他选入即可。
【Fixed Factors框】
即固定因素,说的通俗一些,就是--哎呀,我都不知道怎么解释好了,这样,如果你搞不明白,那么绝大多数要分析的因素都应该往里面选。这里我们要分析的是group和food两个变量,把他们全都给我抓进去!
固定因素指的是在样本中它所有可能的取值都出现了,比如例中的food,只可能有1、2、3这三个值,并且都出现了,就被称作固定效应;而相对应的随机效应的因素指的是所有可能的取值在样本中没有都出现,或不可能都出现,如本例中的group,实际上总体中当然不可能只有这8窝,因此要用样本中group的情况来推论总体中group未出现的那些取值的情况时就会存在误差,因此被称为随机因素。我这里让group也选入固定框是基于下面的事实:这样做统计分析的结论是完全相同的。不同的只是推论的那部分。
【Random Factors框】
用于选入随机因素,如果你弄不明白,假装没看见他就是了。
【Covariate框】
用于选入协方差分析时的协变量,现在还用不到,不过下一个例子我们就要给他送礼了。
【WLS Weight框】
即用于选入最小二乘法权重系数。别理他,根据我的理解,只有统计分析的变态狂才会想起来用他(如有雷同,纯属巧合)!
【Model钮】
单击后出现一个对话框,用于设置在模型中包含哪些主效应和交互因子,默认情况为Full factorial,即分析所有的主效应和交互作用。我们这里没有交互作用可分析,所以要改一下,否则将作不出结果来。将按钮切换到右侧的custum,这时中部的Build Term下拉列表框就变黑可用,该框用于选择进入模型的因素交互作用级别,即是分析主效应、两阶交互、三阶交互、还是全部分析。这里我们只能分析主效应:选择main,再用黑色箭头将group和food选入右侧的model框中,如果对这段叙述不太清楚,请参考下面的动画。

该对话框中还有两个元素:左下方的Sum of squares框用于选择方差分析模型类别,有1型到4型四种,如果你搞不清他们之间的区别,使用默认的3型即可;中下部有个Include intercept in model复选框,用于选择是否在模型中包括截距,不用改动,默认即可。
【Contrast钮】
弹出Contrast对话框,用于对精细趋势检验和精确两两比较的选项进行定义,在这里,该对话框比单因素方差分析的时候还要专业,使用频率也更少,反正我都没用过,就干脆就不介绍了。
【Plots钮】
用于指定用模型的某些参数作图,比如用food和group来作图,用的也比较少(指国内,因为它主要是用来做模型诊断用的)。
【Post Hoc钮】
该按钮弹出的两两比较对话框和第7章单因素方差分析中的一模一样,不再重复。本题对food作两两比较,方法为SNK法。
【Save钮】
将模型拟合时产生的中间结果或参数保存为新变量供继续分析时用,可保存的东东有预测值、残差、诊断用指标等。
【Options钮】
当然是定义选项啦!可以定义输出哪些指标的估计均数、并做所选择的两两比较,还有其他一些输出,如常用描述指标、方差齐性检验等。
好了,都解释完了,再重复以下,我们所作的操作为:
- Analyze==>General Lineal model==>Univariate
- Dependent Variable框:选入weight
- Fixed Factors框:选入group和food
-
Model钮:单击
-
Custom单选钮:选中
-
Model框:选入group和food
-
单击OK
-
Post Hoc钮:单击
-
Post Hoc test for框:选入food
-
SNK复选框:选中
-
单击OK
-
单击OK
8.1.2 结果解释
按照上题的操作,结果输出如下:
Univariate Analysis of Variance

这是一个所分析因素的取值情况列表,没有什么不好懂的。

现在大家看到的是一个典型的方差分析表,只不过是两因素的而已,我来解释一下:首先是所用方差分析模型的检验,F值为00.517,P小于0.05,因此所用的模型有统计学意义,可以用它来判断模型中系数有无统计学意义;第二行是截距,它在我们的分析中没有实际意义,忽略即可;第三行是变量GROUP,可见它也有统计学意义,不过我们关心的也不是他;第四行是我们真正要分析的FOOD,非常遗憾,它的P值为0.084,还没有统计学意义。尽管不太愿意,我们的结论也只能是:尚不能认为三种营养素喂养的小白鼠体重增量有差别。
上表的标题内容翻译如下:
|
变异来源 |
III型方差SS |
自由度 |
均方MS |
统计量F |
P 值 |
|
校正的模型 |
2521.294 |
9 |
280.144 |
11.517 |
.000 |
|
截距 |
74359.534 |
1 |
74359.534 |
3056.985 |
.000 |
|
GROUP |
2376.376 |
7 |
339.482 |
13.956 |
.000 |
|
FOOD |
144.917 |
2 |
72.459 |
2.979 |
.084 |
|
误差 |
340.543 |
14 |
24.324 |
||
|
合计 |
77221.370 |
24 |
|||
|
校正的合计 |
2861.836 |
23 |
Post Hoc Tests
FOOD
Homogeneous Subsets

现在是两两比较的结果,方法为SNK法,由于前面总的比较无差异,所以这里三种食物均在一个亚组内,检验无差异,P值为0.121。
![]() 前面方差分析FOOD的P值不是0.084吗?这里又是0.121,究竟哪个为准?两两比较只是近似的比较结果,应以前面方差分析的P为准,不过这两个P值不会在检验结果上发生质的冲突,一般只是大小不同而已。
前面方差分析FOOD的P值不是0.084吗?这里又是0.121,究竟哪个为准?两两比较只是近似的比较结果,应以前面方差分析的P为准,不过这两个P值不会在检验结果上发生质的冲突,一般只是大小不同而已。
好了,上面是正确的结果,如果model选择是采用Full factor又如何呢?会得出方差分析表如下:

看到了吗?由于所谓的交互作用将自由度给全部“吃”掉了,没有误差可用于统计分析,什么结果也做不出来。
§8.2 协方差分析
例8.2 某医生欲了解成年人体重正常者与超重者的血清胆固醇是否不同。而胆固醇含量与年龄有关,资料见下表。
| 正常组 | 超重组 | ||
|
年龄(X1) |
胆固醇(Y1) |
年龄(X2) |
胆固醇(Y2) |
|
48 |
3.5 |
58 |
7.3 |
|
33 |
4.6 |
41 |
4.7 |
|
51 |
5.8 |
71 |
8.4 |
|
43 |
5.8 |
76 |
8.8 |
|
44 |
4.9 |
49 |
5.1 |
|
63 |
8.7 |
33 |
4.9 |
|
49 |
3.6 |
54 |
6.7 |
|
42 |
5.5 |
65 |
6.4 |
|
40 |
4.9 |
39 |
6.0 |
|
47 |
5.1 |
52 |
7.5 |
|
41 |
4.1 |
45 |
6.4 |
|
41 |
4.6 |
58 |
6.8 |
|
56 |
5.1 |
67 |
9.2 |
该题选自《医学统计学》第二版第七章。考虑到统计分析对数据格式的要求,我们这里建立三个变量:GROUP表示组别,AGE代表年龄,CHOL则表示胆固醇。
8.2.1 分析步骤
由于协方差分析涉及到许多较深的统计理论,这里我只好采用照本宣科的方法,告诉大家如何作,而不作过多解释,欲进一步了解原理的朋友请参考《医学统计学》原书。
首先应进行预分析,了解资料是否符合协方差分析的要求,最重要的一点就是看age的影响在两组中是否相同,这可以用age与group是否存在交互作用来表示。对该问题,粗糙的方法可以是作分组散点图,差不多就可以,也可以进行预分析,看交互作用有无统计学意义,这里用后一种方法中最为精确的步骤来讲解。
预分析步骤:
-
Analyze==>General Lineal model==>Univariate
- Dependent Variable框:选入chol
- Fixed Factors框:选入group
-
Model钮:单击
-
Custom单选钮:选中
-
Model框:选入group、age和group*age(后者用interaction方法就可选入)
-
Sum of squares列表框:改为Model I
-
单击OK
-
单击OK
该步骤用于判断group和age间是否存在交互作用,如存在,则协方差分析的条件不满足,分析不能继续。注意这里选择了Model I,从而拟合结果和模型中变量的引入顺序有关,即侧重点在group对chol的影响大小和交互作用上。
8.2.2 结果解释
预分析步骤的结果如下:
Univariate Analysis of Variance


上表显示交互作用无统计学意义,而且P值非常大,因此交换group和age多半交互作用也无统计学意义,因此可以不继续作预分析了,当然,严格的步骤应当交换两者的顺序继续进行预分析。
正式分析步骤:
-
Analyze==>General Lineal model==>Univariate
- Dependent Variable框:选入chol
- Fixed Factors框:选入group
-
Model钮:单击
-
Custom单选钮:选中
-
Model框:选入group、age
-
Sum of squares列表框:改为Model III
-
单击OK
-
Options钮:单击
-
Displsy means for框:选入group
-
Compare mean effects复选框:选中(下面的区间调整方法就用LSD(none)即可)
-
单击OK
-
单击OK
Univariate Analysis of Variance


这是正式的统计分析结果,显示group和age都对胆固醇含量有影响,P值分别为0.038和小于0.001。
Estimated Marginal Means

这是两组的修正均数及相应的可信区间,显然超重组的胆固醇均值较高。下方的提示表明该修正均数是按年龄为50.2308岁的情形计算的。
§8.3 其他较简单的方差分析问题
其他各种不太复杂的方差分析,如交叉设计的方差分析、析因设计的方差分析等的菜单选择和统计结果的解释我就不一一详细讲解了,大家举一反三,类似上面的方法就可以作出来。这里只是列举对于初学者来说可能有用的几个问题:
-
需要分析的影响因素可以都选入fixed factor框,如果不是复杂的模型,一般分析结果不会有误。
-
方差分析模型多数情况下要选model III,但这在数据存在缺失值、设计不平衡等情况下要慎重考虑,因为此时往往会要求模型进行详细的设置。
-
model的设置对分析是非常重要的,如果设置不正确,可能什么都做不出来,比如无重复数据的方差分析纳入了交互作用、析因设计的方差分析纳入了设计中不存在的因素,就会做不出结果。
-
一般线性模型的复杂性是超出大家想象的,实际上这几个敲门就有误人子弟之嫌。千万不要以为读懂了以上内容就可以打遍天下了,一但有存在疑问的内容,一定要查阅有关统计书籍,并在必要时请教专业统计分析人员。
本网站所有内容来源注明为“梅斯医学”或“MedSci原创”的文字、图片和音视频资料,版权均属于梅斯医学所有。非经授权,任何媒体、网站或个人不得转载,授权转载时须注明来源为“梅斯医学”。其它来源的文章系转载文章,或“梅斯号”自媒体发布的文章,仅系出于传递更多信息之目的,本站仅负责审核内容合规,其内容不代表本站立场,本站不负责内容的准确性和版权。如果存在侵权、或不希望被转载的媒体或个人可与我们联系,我们将立即进行删除处理。
在此留言