
医疗大数据:巨大商机的背后
2013-11-23 MedSci MedSci原创

当每个老百姓都可以随时管理、查询自己的健康医疗数据,而且这样的数据将不局限于体检结果、就诊记录,还可以衍生到你的基因数据,你的日常健康行为监测数据,医疗大数据的价值才能真正发挥,人类对自身的认识也将上一个新的台阶。 最近几年,科技界、政经界在无数的论坛、课题、媒体中,在讨论着一种新的“智慧” - “云物移大智”!这种智慧依赖四个工具:云计算
当每个老百姓都可以随时管理、查询自己的健康医疗数据,而且这样的数据将不局限于体检结果、就诊记录,还可以衍生到你的基因数据,你的日常健康行为监测数据,医疗大数据的价值才能真正发挥,人类对自身的认识也将上一个新的台阶。
最近几年,科技界、政经界在无数的论坛、课题、媒体中,在讨论着一种新的“智慧” - “云物移大智”!这种智慧依赖四个工具:云计算、物联网、移动、大数据。在我看来,这四个“工具”,都可以浓缩为一个字 – “网”!因为,这一切的背后,都缘起于互联网的诞生!所以,“云物移大智”也是一种“网络智慧”!
在上面四个工具里,前面三个更趋近“工具”的概念,其中“大数据”的地位比较特殊,处在“工具”和真正“智慧”之间。有了大数据的挖掘,才能有“网络智慧”的直觉!此时,一个闭环的反馈系统正式产生,“数据”从人群中来,通过“云物移大智”,又还施彼身,于是,人类这个“系统”因为这个闭环反馈的车轮,快速滚向那个“奇点”!
这里不得不说,这种“闭环反馈”的完美案例,早在10多年前,Google 创立时,就已开始。看过吴军的《浪潮之巅》,就知道,Google 是一台完美的印钞永动机。它直接利用了人类互联网的大数据 – 由人类开发制作的各种网站上的信息,通过大数据整合挖掘,变成一种搜索工具返还给人本身。形成“闭环”的轮子,不断被搜索饥渴的互联网人所推动,越滚越大。同时,Google 还做了另一个闭环轮子 - 商业广告需求与搜索需求的自动化匹配。如果把社会商业网络比作一个人体的话,前者是“气”,后者是“血”。中医里说:气为血之帅,血为气之母!可见两者是皆然不可分的。
Google 是互联网商业模式里,最佳的“气血”案例!同样,阿里在线交易平台是“气”,支付是“血”,物流是“质”,老马必须完成这个三个闭环反馈才功德圆满!
说到这里,我想告诉大家的是,大数据本身没有价值,你至少得发现信息流- “气”和资金流 – “血”两个轮子的闭环反馈圈,听让他们自己转起来,才能真正获得价值!
凯文.凯利(KK)在《失控》的第22章,“预言机”(PREDICTION MACHINERY)里,曾提到“信息就是数据,数据一旦流动,就创造出透明。社会一旦联网,就可以了解自己。”所以,很多热衷与“大数据”概念的人,他知道哪里有数据,却没有办法去促成数据的“流动”!
所以,第一要义,数据如何才能形成“流动”?它的驱动力在哪里?以医疗健康这个行业为例,让我们看看,现在很热的医疗健康大数据,到底流动性如何!
如果把医疗健康领域看做一个生态环境,我们可以简单分出四个“物种”: Doctor – 医生(简称“D”);Consumer – 消费者(简称“C”);Hospital – 医疗机构(简称“H”);Government – 政府(简称“G”),如下图:
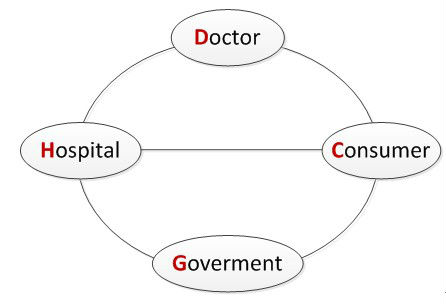
上图的四个“物种”分为两类,H 和 G 为机构,D 和 C 为个人。这样一个生态系统,其目的就为了一件事:如何让 C 保持、改善其 Body 的健康、治疗疾病并延寿。这个生态系统里的基础数据,就是所有 C 端的生命数据集合!这里又分两个维度,从“广度”上,同一个数据项的 C 端的人数,例如:你拥有 三千万人 的血压值;从“深度”上,指某一个 C 端用户其时间轴(从生到死)的连续数据,例如:有些量化自身运动的玩家,拥有自己10年的尿酸变化数据。以前,G (政府)这个层面大量做的是“广度”型数据,例如:艾滋病、结核病的全国分布;未来,面向个C端的“深度”型数据将是一个方向!
就当前情况来看,C 端数据的主要产生地在 H (医院)端,数据挖掘和反馈主要在 D(医生) 端,其数据闭环路径为: C => H => D => C 。由于 D 的主要工作地点也在 H,因此 H 必然会在此闭环运转下,越长越大!同时,中国 H 又隶属不同的体系,如: 军队系、大学系、地方希、部属系,所以作为卫生主管部门的 G ,对 H 的影响也有限。综合起来,H 是该生态系统里的“关键物种”!也是难以撼动的物种!这就导致一个局面,要做医疗领域面向 H 的平台,是非常难的事!这也是为什么互联网对医疗界的影响远不如银行、电子商务那么快速的原因!
尽管如此,情况依旧在发生改变,我们看看目前“云物移大智”在医疗健康领域是怎么展开的。我们已经基于上面的那张医疗生态图,做模式分析:
2H :(可以理解为 To Hospital)即:直接为医院提供各类“云物移大智”的产品,如:HIS、LIS、PACS、院内移动办公、医院手机版…… 特点是:销售驱动,数据沉淀在 H 内,打破地方壁垒难,产品需求千差万别,大部分厂商是在卖“IT人力”服务;
2D :服务于医生的科研、学术类为主,特点:专业性高,行业窄,工具化,数据产生少;
D2D : 医生社区类,为医生提供交流学习、科研合作的场所。特点:起步难,粘性好,容易一家独大,医疗人力资源和医药广告是其“血”脉。
D2C:搭建 医生与患者之间的桥梁。目前主要存在的是医生点评类和在线初级问诊及健康咨询类,前者形成对医生的评价数据,后者形成用户初级健康病历数据。特点:D端以年轻医生为主,高资历医生难以留住,用户参与性有待观察,变现模式还比较模糊。
2C: 往年以媒体类健康宣传、在线医药电子商务为主,近期,自助式健康管理,结合可穿戴设备的自我健康监测刚起步,目前核心问题在于自我管理的需求驱动力不够,自我管理的咨询反馈的服务不够,反馈速度及治疗不高。
C2C:患者社区,患者医学维基等模式,国内刚开始。同样,社区类的起步都较慢,关键是在于社区的成长性,以及能否留下有价值的数据。患者社区与普通社区最大的区别在于专业性,
H2C:搭建医院与患者之间的平台,包括方便患者就医、出院随访、远程疾病预警及健康监测,该模式下,需要产品、服务、医院营销的综合实力。特点:复制速度是核心、具备刚性需求,风险规避要做好。
事实上,以上各种模式都已有一批玩家,从创业公司到上市公司,但还没有一种模式可以拍胸脯说,我是医疗健康界“云物移大智”的典范。相对来说,H 端的市场比较成熟,C 端的市场还处于起步探索阶段,互联网对医疗行业带来的影响,给老百姓带来的好处还没体现出来。一个显而易见的事实:虽然国家医改投入巨资建立区域医疗数据中心,大力倡导给每个老百姓建立电子健康档案(EHR – Electrical Health Record),但实际有多少老百姓知道了,用上了?所以,看似红火的“医疗大数据”,其实名存实虚。究其原因:作为这个生态系统里的关键物种 – H,没有彼此分享和交换数据的动力!使得推动医疗领域数据流动的“气”严重不足。
另一方面,一直以来有个法律上的模糊地带:当一个老百姓去了医院看完病后,哪些数据是归属他可以带走的,哪些数据是归属医院的,在网络信息时代的今天,缺乏界定。设想一个场景,若某一天,每个去医院(或其他医疗健康机构)看完病的C端消费者,出医院时,都可以用 U 盘把他在这个医院所发生的EHR 数据copy走,U 盘上是一个 .ehr 文件,可以如同 .doc 的WORD文档一般,被一个标准EHR浏览器打开。他可以直接分享这个文件给想咨询的医生,也可以与同病相怜的朋友共享,或归入他自己的 .ehr 文档库,会是怎样一个场景?此时,数据的隐私性将获得尊重,同时数据的价值才能真正开始显现。
我相信终有一天,一个开源的 .ehr 浏览器将会诞生,EHR 电子文档格式也将开放,每个老百姓都可以随时管理、查询自己的健康医疗数据,不是在遥不可及的第三方,而是在他自己手里。而且这样的数据将不局限于体检结果、就诊记录,还可以延生到你的基因数据,你的日常健康行为监测数据。你将从法律上拥有获得这些数据的权利!也许,一直要到这一天,医疗大数据的价值才能真正发挥,人类对自身的认识也将上一个新的台阶。
大数据之伤——小数据思维
1980年之前,临床医师们主要依赖“经验”、“直觉”以及“触摸不到的线索”来判断一个发烧了的小孩子到底是由较轻的疾病(如感冒)还是由比较严重的疾病(如急性肺炎或脑膜炎)引起的。换句话说,他们靠直觉来看病。在1980年,一个由研究者组成的小组研究了那些有经验的儿科医生是如何为他们的病人诊断的。他们发现了那些杰出的医师在直觉中参考了“输入信息”,而那些缺乏经验的医师在试图可靠地试用这些“输入信息”时就显得过于主观了。
在随后的研究中,研究人员从精确度和客观性两个方面上加强了他们的系统。在这个系统中,那些正在接受培训的儿科医师能够像有经验的医师那样接触到很多因严重疾病而导致发烧的儿童。事情发生了根本上的变化:直觉的建立被质化和量化地形成了一种形式,并且这种形式可以被那些经验并不丰富的医生所利用。如今,几乎所有正在为发烧儿童看病的医生都在证实这精妙的发现。
如果我们把目标确定为为每位儿童的每次就诊都提供最好的治疗,那么我们需要的就不仅仅是直觉和专业的技能了,因为人无完人。基于证据的医疗方法(EBM)通过把临床研究整合进治疗准则来帮助医师提高治疗水平。然而就普遍意义来说,EBM一般是基于“小数据”的研究——与动辄数十万或数百万的大数据不同,一个大型的EBM则是包含了数千例病例的系统。在这样的小样本规模系统中输入信息必须被良好地定义和形式化,随之而来的结果便是包含了所有这些信息的治疗准则在解释病人与病人之间的差异时就显得力不从心。因而EBM有时被人们嘲笑为“菜谱式治疗”,医生们只是机械地遵循着这些治疗的“配方”来治病。鸡肉与菠菜对于一些人来说也许是顿美味,但是当我们要为一位素食主义者上菜时又该怎么办呢?
大数据的容量足够用来创造更加个性化的“治疗菜谱”。利用一个容量为5亿人的数据集,你可以为一个体重超重且高胆固醇每天必须服用阿司匹林和立普妥的35岁男人,或者为一个与上述情况完全相同但是体重偏轻的人定制治疗方案。
大数据也可以允许我们通过在粗略的未经处理的数据集中逐条比对来发现微小但是强有力的线索,从而进行分析研究。小数据集中通常不能处理粗糙的原始数据,因为它不能分辨“心梗”与“心肌梗死”的区别,即便他们指的是同样的事情。并且由于在小数据集中只能使用单一的术语,使得我们无法做出确凿的归纳。同时小数据集也无法支持需要识别“心梗”与“心肌梗死”是同一种术语的研究。小数据集同样无法支持我们使用很细节的线索作为输入,因为它们在数据集的发生具有太大的随机性--确凿的归纳是无法从这样的小样本数据集中得到的。
目前有越来越多的争议在讨论大数据是否正在取代直觉在医疗中的地位。无论怎样,大数据仍是我们最大的希望--计算机可以在模仿人类专家直觉方面跟进一步,那时我们就再也不用依赖EBM这样的小数据集了。真正的问题并不是大数据正在威胁医疗中的直觉,而恰恰相反,是在于我能未能做到这一点。我们如今在医疗领域并未过于依赖大数据,因为这的确需要大数据量,而医学研究者们手中并没有真正的大型临床数据集。
建立,维护,标识以及保密临床临床数据集的代价太高昂了。泄露数据集信息的惩罚很重,而建立这样数据集的利益却几乎不存在。即便是政府支持的健康信息流通项目通常也不进行数据统计。取而代之的是,这些系统被用作让登陆者进入一个外部系统,一次只能取回一位患者的数据,并且得到的数据通常是摘要形式的。大数据分析是无法在这样的体系中实现的。
然而,大数据量医疗数据集受到的最大壁垒是医疗信息中盛行的所谓“最佳实践准则”,这一准则已经落后于其他行业一二十年了。医疗信息体系仍在持续强化使用陈旧的数据屏障,而这屏障正是维持“小数据集”研究的基础。在这个体系中,只有通过审核的,标准的,被编辑过的数据才能被接收——这里没有任何粗糙的原始数据!随之产生的数据集便是小数据集,因为屏障式的处理过程是强化数据源的瓶颈,由于缺乏一致性,许多可用的数据被拒之门外。这个屏障创造了同质化的数据,而排除了能使系统真正有用的多样性,这就如同白面包一样——一个被滤去了谷物最好营养物质的空空的净化盒。如果在大数据中使用了这样的屏障,谷歌和亚马逊就不可能成功,原始的大数据正是他们成功的原因。
除非每个医生都同时拥有无与伦比的直觉,否则计算机就应该用来提供更好的医疗。如果我们在处理过程中摒弃小数据思维,并开始建立真正的大数据,那么大数据在医疗支持中将会发挥更加巨大的作用。
医疗大数据发展前景乐观
孙卫副局长则发言指出,十八届三中全会后释放了非常多的积极信号,其中之一就是让市场起决定性作用,而不是以前让市场只起调节作用,上升了一个层次。此外,针对开放医疗市场,三中全会公报中强调是有计划的开放,而不是无限制的开放,接下来的一段时间或将迎来社会资本进入医疗领域的新一轮高潮,作为公立医院的管理者们应该有所准备,积极应对。
对于大数据采集与分析,以及新技术对医疗行业可能产生的影响,众专家也表现出十分积极乐观的态度。
王衫院长认为,对于大数据时代应该保持谨慎的乐观,之所以“谨慎”,是因为针对大数据强调4个“V”,即容量(Volume),速度时效性(velocity),多样性(Variety),真实客观性(Veracity),但作为医院来讲,直到目前仍然是以结构化的数据为主,比如电子病历、影像检查和资料等等,这离非结构化或半结构的大数据还有一定的距离,比如病人体温的采集现在仍然还是采用人工录入的方式,实际上如果通过物联网、感应设备以及语音等非结构化的大数据采集方式实现病人体征的自动化采集;此外,大数据绝不仅仅只是针对来医院就诊的患者,大数据肯定是包括全人群的。“一个人如果从出生开始就能够完成健康信息的自动采集,就能够通过大数据的分析对疾病的预防、发展和治疗产生积极的影响。”
李景波院长则从区域医疗数字化的角度阐述了自己对大数据的认识。他表示,单纯某一家医院实现数字化是不行的,区域医疗数字化将是未来发展的大趋势,除了医院内部电子病历、物联网的建设,整个区域内民众健康档案的信息化数字化建设也是十分重要的。“云计算、物联网、移动互联网等技术的发展,都将给大数据业务提供技术支撑。比如将所有的影像学资料进行大数据分析,这些大数据总结出来的诊断经验就可以用于新医生的培训,帮助这些年轻人快速成长。”
小提示:本篇资讯需要登录阅读,点击跳转登录
版权声明:
本网站所有内容来源注明为“梅斯医学”或“MedSci原创”的文字、图片和音视频资料,版权均属于梅斯医学所有。非经授权,任何媒体、网站或个人不得转载,授权转载时须注明来源为“梅斯医学”。其它来源的文章系转载文章,或“梅斯号”自媒体发布的文章,仅系出于传递更多信息之目的,本站仅负责审核内容合规,其内容不代表本站立场,本站不负责内容的准确性和版权。如果存在侵权、或不希望被转载的媒体或个人可与我们联系,我们将立即进行删除处理。
在此留言
本网站所有内容来源注明为“梅斯医学”或“MedSci原创”的文字、图片和音视频资料,版权均属于梅斯医学所有。非经授权,任何媒体、网站或个人不得转载,授权转载时须注明来源为“梅斯医学”。其它来源的文章系转载文章,或“梅斯号”自媒体发布的文章,仅系出于传递更多信息之目的,本站仅负责审核内容合规,其内容不代表本站立场,本站不负责内容的准确性和版权。如果存在侵权、或不希望被转载的媒体或个人可与我们联系,我们将立即进行删除处理。
在此留言




#医疗大数据#
68